Why organizations must elevate multi-region architecture from a reliability afterthought to a core business enabler as AI transforms risk, growth, and competitive differentiation.
Executive Summary
For enterprises investing in AI, the shift to multi-region cloud deployments is no longer just a checkbox for disaster recovery or regulatory compliance. The AI era has fundamentally changed the game: latency has become existential, regulatory boundaries are tightening, and the economic fallout from downtime is multiplied by deeply integrated, intelligent systems. Staying single-region carries a new kind of business risk—one that impacts growth, reputation, regulatory standing, and the ability to deliver seamless global AI-powered experiences. Multi-region by design is now a platform for strategic resilience, empowered innovation, and global business trust. If your AI ambitions are global, your infrastructure must be as well.
1. Introduction: Why Multi-Region Matters Now
For the past decade, multi-region deployments have been viewed through a familiar lens: mitigate the blast radius of outages, serve customers with low latency, satisfy national data regulations, and meet high-availability SLAs. In this paradigm, multi-region was an insurance policy: sometimes expensive, usually justified only for the most critical workloads, and often viewed as a nice-to-have for less regulated industries.
That calculus has changed. AI brings radically different characteristics to enterprise architecture:
- Inferencing and model serving are increasingly latency-critical. Each token of the generative process must stream interactively, or user experience suffers.
- AI adoption increases blast radius. A model outage is more than a feature degraded—it can paralyze entire smart workflows, digital products, or even business units.
- Model and data locality shape competitive differentiation. The best AI-powered experiences demand proximity—not only to user data but to regional capacity, edge nodes, and low-latency GPU endpoints.
- Sovereignty requirements are stricter and more dynamic. Data residency is now matched by “model residency,” with some jurisdictions already mandating local AI inference and training.
- Regional capacity constraints are real and unpredictable. The rush for GPUs is causing competition at the cloud region level, necessitating diversification as a hedge against scarcity.
In short, the AI era redefines the “why” for multi-region. It’s not just about not failing. It’s about enabling tomorrow’s AI-powered business models, scaling trust, and staying ahead of the risk curve.
2. How AI Changes the Multi-Region Conversation
AI elevates multi-region from a specialist pattern to a strategic architecture. Here’s how:
1. AI Inference Demands Ultra-Low Latency
Generative AI workloads often serve tokens interactively. The difference between 50ms and 350ms round-trip latency is no longer just an engineering detail—it’s a make-or-break product experience. Multi-region, with intelligent routing, brings inference endpoints closer to users and regional processing, minimizing “AI lag.”
2. Global Proximity is Table Stakes
Digital banks, SaaS platforms, and consumer AI offerings serve users over continents—users expect instant experiences. Regional proximity to both models and data stores is needed, not just to reduce latency, but to comply with the growing matrix of regional privacy and financial regulations.
3. AI-First Workloads Have Increasing Shared State
As organizations layer on retrieval-augmented generation (RAG), multi-modal cognitive pipelines, and session-aware AI, dependencies on distributed vector databases, orchestrators, and context stores intensify. Each of these adds new dimensions to the region-resilience, data replication, and state consistency problem.
4. Capacity and Contention
The “GPU gold rush” means not all regions are equally equipped for AI. Organizations must plan for capacity failover, where critical model serving shifts to alternate regions if a primary runs out of essential AI hardware.
5. Blast Radius and Operations
Outages in one region propagate far beyond. A single-region failure can now take AI-powered processes, automation, and decisioning offline across the globe. The business blast radius is magnified.
6. Regulatory and Data Geofencing
AI regulation is extending from data to model. A model trained or served in the “wrong” jurisdiction may be non-compliant. Multi-region makes it possible to physically and logically segment AI artifacts along jurisdictional boundaries.
Key Takeaway
In the era of AI, the question is no longer “how resilient?” but “how globally capable, responsible, and trusted?” Multi-region is the new baseline for platform maturity, not a late-stage optimization.
3. Strategic Business Case for Multi-Region Design
Architectural decisions are business decisions. Why invest in multi-region now, and what are the real risks—and rewards—of staying single-region in the AI era?
Multi-Region as Strategic Differentiator
- Revenue protection and growth: Customers, B2B partners, and regulators increasingly demand assurance of business continuity. Outages undercut trust and erode competitive position—especially as AI services become the face of your organization.
- Global user experience: AI-fueled applications and products are globally interactive. Serving a Singapore-user from a US data center means lost conversions, frustration, and lower engagement.
- Compliance and regional expansion: Multi-region enables entry into new markets where data and AI model residency are prerequisites. It feels like a technical requirement but is, in reality, a “passport” for market access and expansion.
- Operational risk reduction: AI increases blast radius and operational entanglement; diversifying regional dependencies reduces systemic risk far beyond classic DR.
- Capacity risk mitigation: The AI era has created localized “GPU crunches,” where the difference between serving users and disappointing them depends on the ability to rebalance workloads across regions.
- Brand trust: AI outages are not just technical events but reputational ones. For regulated or customer-facing sectors, repeated AI incidents can have outsized negative impacts on trust and long-term value.
Fictional Example: Global Retail AI
Imagine a multinational retailer using AI for logistics, personalization, fraud detection, and customer engagement across 40 countries. When a US-East cloud region has a GPU shortage, their recommendation engine fails for millions of users worldwide. Worse, when a Europe-wide data residency law changes overnight, they lack the capability to segregate or migrate model serving in time. Outages cascade, leading to lost revenue, regulatory headaches, and a hit to digital reputation. With a multi-region architecture, workloads could both failover and dynamically localize, turning compliance and capacity into competitive levers rather than liabilities.
Executive Insight:
Multi-region is as much a business enablement strategy as a resilience tool. In a world where AI-generated value—and risk—is global, so must be your infrastructure.
4. Technical Architecture Patterns and Trade-Offs
A. Deployment Topologies
- Active-Active:
All regions serve users and traffic simultaneously, providing the highest SLA and lowest latency, with automatic failover and global traffic steering. - Active-Passive:
One primary region carries all production workloads; one or more “warm” regions stand by, typically lagging slightly behind and activated during failover. - Single-Region:
All workloads serve from a single cloud region, with offsite backups or cold standbys at best.
Table 1: Multi-Region Deployment Matrix
| Characteristic | Single-Region | Active-Passive | Active-Active |
|---|---|---|---|
| User Experience | Variable (latency, risk) | Improves on failover | Lowest latency globally |
| SLA / Availability | Lower | High (after failover) | Highest, instant failover |
| Cost | Lowest | Higher (standby cost) | Highest (fully loaded) |
| Complexity | Low | Moderate | High |
| Regulatory Coverage | Minimal | Moderate | Maximum |
| Blast Radius | Largest | Controlled | Minimal |
| Suitable AI Workloads | None / Non-critical | Some | All mission-critical |
B. Core Design Areas
- Traffic Steering and Global Load Balancing:
Leveraging anycast DNS, region-aware gateways, and client-based routing. Inference and model endpoints must be globally advertised and region-aware. - Data Replication:
Strongly consistent, eventually consistent, or region-locally persistent—applied depending on workload. Vector DBs and AI context stores have different needs than OLTP ledgers or user profiles. - State Management:
Key-value session data, embeddings, and context must flow between regions with carefully managed latency and consistency guarantees. - Network and Identity:
Global, secure and private interconnected networks; cross-region secrets management; identity and control-plane replication that avoids central points of failure. - Observability and Operations:
Global, federated telemetry collection and incident response with region-aware dashboards and automated failover testing.
AI Application Multi-Region Topology Summary
- User connects via region-local entry point (DNS or edge routing).
- Regional load balancer forwards to closest AI inference gateway.
- Each region contains:
- AI inference endpoints (Llama/LLM API on GPU nodes)
- Model context cache (Redis/Memcached)
- Vector database for semantic search (replicated or sharded)
- Data pipeline orchestrator (regional or cross-region)
- Local/regional observability/log shipping
- Actively replicating metadata between regions; strong/weak consistency options per workload.
- Global policy and identity replicated via cross-region control-plane.
- Operations ‘kill-switch’ enables per-region isolation during incident.
- Service mesh controls east-west and north-south traffic.
5. AI-Specific Design Considerations
AI amplifies region-awareness across the entire technical stack:
- Prompt Orchestration Tier:
Coordinating user sessions and multi-turn tasks across regions, handing off context where needed. - Vector Database and Data Locality:
Indexes for embeddings must be available regionally—with clear policies for replication, sharding, or local persistence. - Caching for Model Inference:
High-throughput LLM queries benefit from per-region short-lived caches for both responses and prompts. - Model Versioning and Policy Guardrails:
Consistency of allowed model versions and filtering/policy engines is required—one region running an outdated, unfiltered model can open compliance holes. - Third-Party Endpoint Dependency:
Where workloads depend on cloud foundation models (e.g., OpenAI, Anthropic), region-by-region endpoint differences in capability, quotas, or latency must be actively managed.
Figure 3: Multi-Region AI Platform Maturity Model
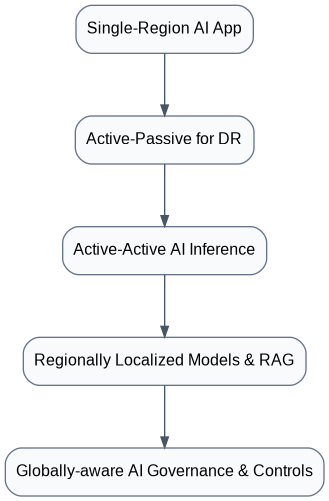
- A: All AI workloads in one region; only backups elsewhere.
- B: Critical AI workloads can failover (manually or automated) to standby region.
- C: Real-time global traffic steering and inference serving; session distribution.
- D: AI training, fine-tuning, and RAG pipelines distributed per region, with context and security compliance.
- E: Integrated governance, audit, safety controls, and model policies synchronized globally, with regional override capability.
6. Common Mistakes and Anti-Patterns
- “Multi-region means we’re resilient” fallacy:
Without deeply tested failover, control plane integration, and data-plane readiness, multi-region can become a false sense of security. - Replication as a magic bullet:
Not all data or context can be copied blindly; avoid dual writes, consistency gaps, and unprepared session handoff between regions. - Regional Dormancy:
Passive regions that are “cold” or lack realistic failover runbooks are almost never ready when truly needed. - Platform-agnostic assumption:
Some AI services (especially SaaS APIs or foundation models) are not truly region-agnostic, so real failover may expose new limits or costs.
7. A Practical Decision Framework
When is multi-region justified, and for what?
Step 1: Map Workload Criticality
Core business, regulated, or customer-facing AI workloads are first candidates. Internal batch jobs or non-interactive analytics can often remain single-region until scale or policy changes.
Step 2: Quantify Regulatory and Latency Drivers
If regulation or customer latency is a primary risk, multi-region is not optional. Otherwise, consider business continuity and cost/benefit balance.
Step 3: Assess Capacity Exposure / “GPU Scarcity”
If your AI ops, especially inference, could be throttled by regionally scoped GPU/AI accelerator limits, prioritize capacity-diversified design.
Step 4: Compare Operational Maturity vs. Overengineering
If your IR/DR runbooks are immature or your SRE/engineering processes can’t yet operate across regions, scale regionally only as fast as your readiness.
Step 5: Sequence the Journey
Start with business-critical AI workloads. Favor stateless services, then advance toward distributed data and stateful AI pipeline replication.
Figure 4: “Do We Need Multi-Region Now?”
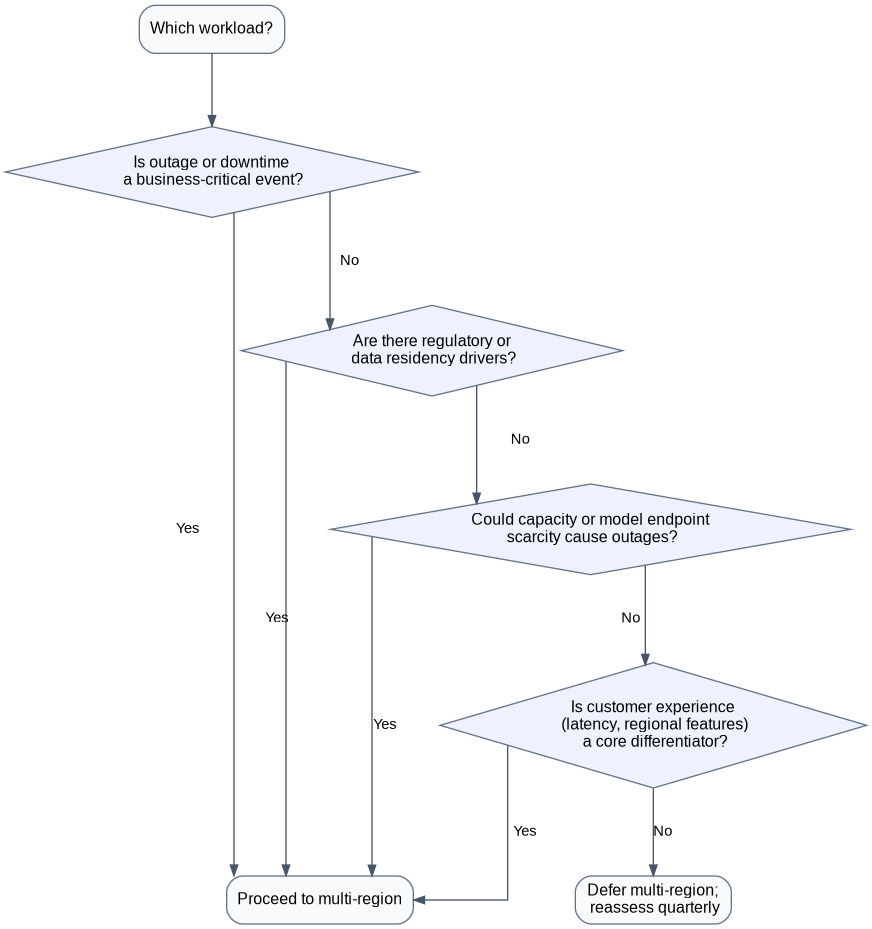
MermaidCopygraph TD
A[Which workload?] --> B{Is outage \ or downtime \ a business-critical event?}
B -- Yes --> C[Proceed to multi-region]
B -- No --> D{Are there regulatory/ \ data residency drivers?}
D -- Yes --> C
D -- No --> E{Could capacity \ or model endpoint \ scarcity cause outages?}
E -- Yes --> C
E -- No --> F{Is customer experience \ (latency, regional features) \ a core differentiator?}
F -- Yes --> C
F -- No --> G[Defer multi-region; reassess quarterly]
8. Final Recommendations
Multi-region is no longer the domain of disaster recovery specialists. In the AI era, it underpins global business, customer trust, and responsible operations—even as it increases technical complexity, operational cost, and architectural demands. For AI-powered organizations, the risk of standing still is now higher than the cost of advancing. Leaders who frame multi-region as a business enabler—not a technical luxury—position their enterprises to win the next generation of the AI-driven global economy.